
Another blog post based on recent client experiences. Last week, I visited a client where we had extensive discussions on data model optimization. As you might know, data modeling in Power BI is one of my favorite topics, so I had an excellent day. It’s also not the first time that I blog about anything data modeling and optimization. If you haven’t read it yet, I recommend reading my previous blog on this topic.
This blog will focus on the need of keys in your tables and primarily your fact tables in your data model. I keep running into data models at customers which are flooded with keys in all tables. For each of them you should ask, do I really need this and could I save it in a different data type for further optimization. In this blog, I will further elaborate on keys in your data model, typical use cases and how these cases can be solved in different manners.

Understanding keys
Let’s first stop at some basic understanding of keys and the concept of keys in tables in general. Overall, we can say that we work with different types of keys in data modeling. Depending on your exact use case, you might use different types of keys. Let’s first have a definition of keys clear:
… Keys are meaningful values that identify records, such as social security numbers that identify specific customers, calendar dates in a time dimension, or SKU numbers in a product dimension.
From IBM – Natural keys
Since I don’t want to make up a new definition of keys, I just searched the world wide web to find some of the different definitions for keys. The one above, kind of summarizes what I had in mind, but I also tend to disagree on some aspects. Especially the meaningfulness of keys is what I would argue about. Sometimes you come across keys being just integers, sometimes some prefixed word concatenated with some random numbers, or even worse the use of GUIDs as keys. I truly don’t know anyone that in the right mind could make anything meaningful out of a GUID.
Also, different names and types of keys might appear in the world of data. Below the most common ones I come across regularly, but most likely this list is still woefully incomplete.
- Business key: the key generated in the source system. Often a concatenation of some letters and numbers or a GUID. CUST_12345 for a customer key for example.
- Natural keys: basically the same as mentioned for business keys.
- Durable keys: a key that has been generated in the data warehouse or data platform to have one unique identified for a employee for example, when this employee left and rejoined and due to that has two different natural keys – but still want to be able to identify this employee as one person.
From Kimball – Natural, Durable and supernatural keys - Surrogate keys: the key generated in the data platform on a dimensional table, typically with the purpose of slowly changing dimensions and data type integer.
From Kimball – Surrogate keys - Alternate keys: Primary key from the source system that loads the data warehouse.
And probably many more.
Usage of keys in Power BI
Now we have a basic understanding of all different types of keys, let’s have a closer look on how keys can be used in Power BI. Basically, the keys are the bases on which you can create a relationship between two tables using one column from each. Usually, this is a relationship between a fact table and a dimensional table.
In this setup, we talk about primary keys and foreign keys, to add just two more to the table.
- Primary key: the key on the one-side of the relationship where it identifies a unique record. Typically, in a dimension to identify a customer or product for example.
- Foreign key: the same key, but on the many-side of the relationship. This identifies that this one product has been sold in this specific sales transaction. But obviously, you’ve sold this product multiple times, to multiple customers and therefore exists multiple times in the table in different records.
Without deep-diving on relationships in Power BI, below an example on how two dimensions are related to a fact table in a star schema data model.
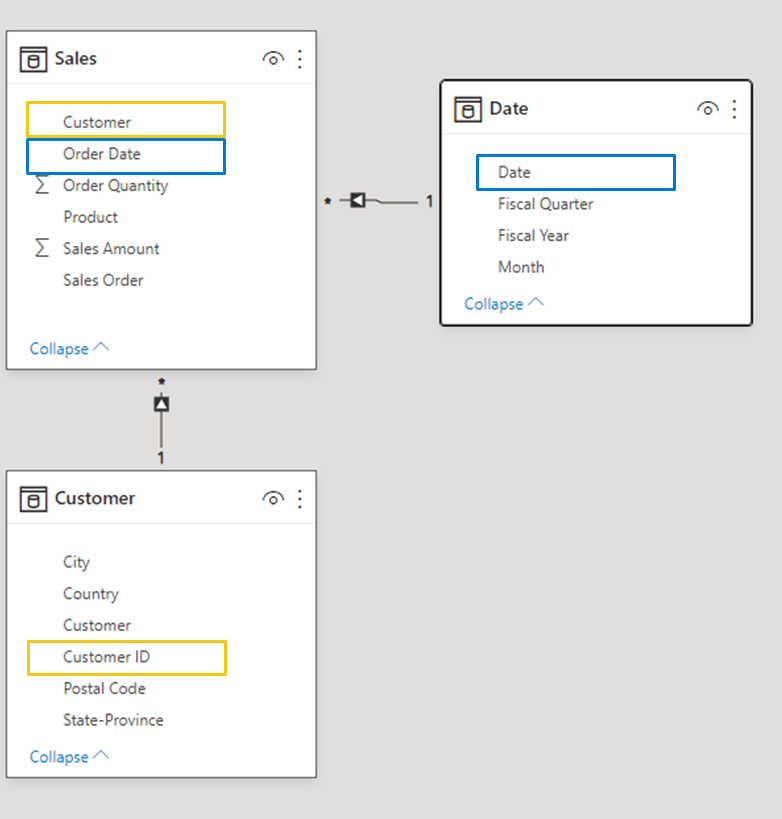
What often is up for improvement?
Ideally, all keys in Power BI are saved as integers in the data model. That simply compresses the best to keep the data model fast performing and well compressed. In case you want to read more about how compression works in the engine of Power BI, I recommend you read the article about the compression of the Vertipaq engine. But for this post, we just take this for granted and accept that integers just work best.
Very often, I come across data model in which keys are not set to integers but are just GUIDs or plain text. Taking into account the article mentioned above, this has a huge hit on your model and will result in a memory eating model. Even when there is a proper key setup, like a surrogate key formatted as integer, often people stuck with the business keys in all tables as well. That means, you have two columns which identify the same record. But why?
Usually, the first argument given is the ability to look up individual records in your source system when analysis shows you that something is off with that one item for example. I get it, that does make sense. But then, only for your dimensions so you can lookup that customer, or that product. But what if you want to lookup that one sales order, which had a key like ORD_12345. If we’re not saving that unique identifier, which is a primary key in the fact table, we cannot look up that one individual sales order. Well, I tend to disagree here. Given the context is provided by the dimensions connected to this fact table, we can still lookup this individual sales order by looking in our source system for an order sold to customer A, on date B, including product C, and so on.
As soon as this argument is off the table, the second one comes up. The customer wants to be able to do a count of orders, so they can compare the number of orders from this year to the orders of last year for example. Again, not a good reason if you ask me. What they try to do, is a distinct count on the order key, which is a very expensive operation to execute by the DAX engine in Power BI. Instead, care about the granularity of your fact table. In the examples used above, each record (or row if you will) in the fact table, represents one individual sales order. To improve performance for your DAX expression and at the same time avoid having that expensive column saved in your fact table, you can just do a count rows.
Wrap up
Following the examples given before, the order key, is a primary key on the fact table containing a unique value for each row. A fact table typically is the table having the most records in your model, and therefore this is a very expensive column about which you can argue if you really need it. As I’ve shown by two examples, typically the reason for customers to keep this column, can easily be solved in different ways which improves the performance as and lowers model size.
So, do you need a primary key, business key, or whatever name we give it in your fact table?
My answer is definitely: No, you don’t! Unless you can come-up with a very good reason now.

Good article, I especially agree with your points to avoid keeping OrderIDs around.
LikeLike
I’ve tried replacing string based keys with integer based surrogate keys but the vertipaq engine always hash encodes the integers anyway—i assume this removes any performance enhancement and only adds compute and additional memory requirement during refresh to handle the merges to substitute the natural keys.
LikeLike
Very interesting article. I was (wrongly?) teached that all dims should have a unique primary key field, even if it’s based on one unique identifier already in the dimension (like a PersonID field). And then reference that key in the fact_table.
LikeLike