
Another week, another event done. This time it was SQL Saturday Helsinki, where I did two sessions. First session was the Power BI cheat sheet explained, and second Storytelling & interactive reporting, one of my favorite sessions to do. Today, another day in Helsinki, but since the weather isn’t that good, it is time for another blog post! I found a small coffee bar, ordered some cappuccinos and wrote this blog post about improving and speeding up your report building.

The case
We, people working with Power BI (also known as Power BI’ers) are all familiar with the case when you apply some more steps in the query editor, Power BI will reload the full table. Totally reasonable, because the new steps need to be applied to each row of the table. But after waiting for a while, we might end up with an error and we can start all over again. In case you do have a large table, this can take a while. So probably you want to test the applied steps on a smaller dataset first.
In case you do have a data source which is deployed across the landscape, you will have a development dataset with only a subset of the data. But in some cases, you don’t have the luxury of multiple data source across the landscape. Then having a smaller dataset during development can be challenging. By taking the steps described in this blogpost, you can improve your report building experience in only a few steps.
During development, having a subset of your data is useful to quickly load your data, check if the applied steps in the query editor result in what you expect it to be and validating the outcomes of your calculations. We can do this by actively filtering the dataset in one of the first steps we take in the query editor.
In this case, I’m going to use a Top N rows to only have a subset of the data available. You can do this with every data source. But to be honest, it is useless when your data source is a flat file since your complete data file will be loaded anyway.
Query folding
Since Power Query (also known as M) is an expression-based language, it will run each expression separately. Each line of code has a dataset as an input, and a dataset as an output which can be called by the name of this line of code. Depending on the data source, Power Query will apply query folding. Query folding groups steps together and execute at the data source. The applied logic will be pushed to the data source and only the result of that logic will be loaded in the Power Query engine on client side.
For flat file this won’t work since they are not queryable. Power BI will always load the full flat file first before it will apply the additional steps. Steps can’t be grouped together and be applied at the data source itself.
On the other side, an Azure SQL database is the perfect example of a data source where query folding will be applied. You can easily check if query folding is applied by right clicking the steps in the query settings (grey bar on the right in the query editor). If the option “view native query” is available, query folding is applied. By clicking this option, you will see the actual query which is fired at the data source.

For all following examples, I used an Azure SQL database with the Adventure Works dataset.
Apply top N
The Power Query function Top N will result in a number of rows to keep (number of rows depending on the applied settings). This function is useful for only keeping a few rows during our development process. The Top N function is one of the default functions which you can apply from the ribbon in the Query Editor window. Under Home, you will find Keep Rows and then click Top Rows. Afterwards we will be asked to enter the number of rows we want to keep.
After applying this step, our table will have less rows. After right clicking the last step we applied in the Query Settings pane, we can click the View Native Query option. This will show us the SQL query which is fired at the SQL Database.

Looking at the native query, the top rows is already selected in the database, before the dataset was even loaded to the Power Query engine.
The steps to get a subset of the data could be applied to each individual table in our dataset. I always prefer to only to this to my fact tables. So, I will do a full load for my dimensional tables, since they are already a distinct set of rows. Besides that, I want to make sure that all my relationships are correct. So, loading a subset of my dimensional tables might be at risk that my relationships will break after loading the full dataset.
Moving to production
Applying a Top N rows to your fact tables if you’re in development, will help you to speed up this process. Simply because you’re only loading a sub-set of the data. At the time we’re moving our solution through the landscape from development to acceptance or production, we want to load the full set of data. We can do this by simply removing this step. But in that case, we still have to do a full load in Power BI desktop which might take a while. Since I’m a little impatient, I don’t want to wait for a full load on my local machine. Let’s make the Top N rows a little bit more dynamic that we can do the full load in the Power BI service!
To be able to change the application of the Top N in the Power BI service, we will change the Power Query code a little bit. By taking the following steps, we make it a more dynamic solution. As a starting point, one of the fact tables already had a Top N rows applied.
- Create a parameter with type True/False.
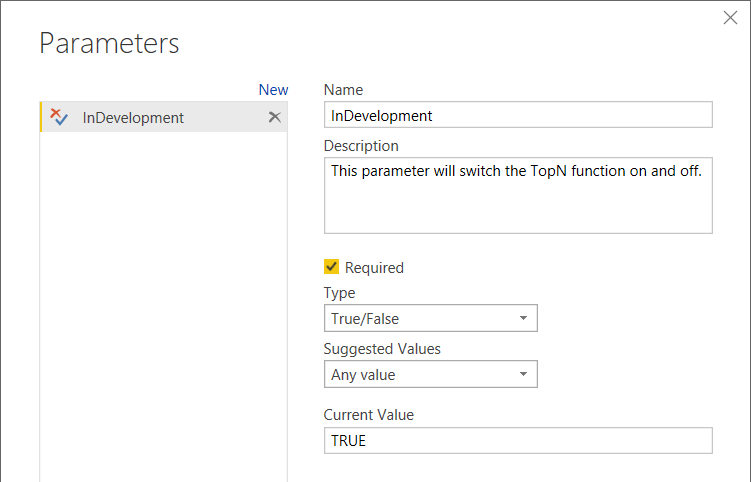
- Set default value of parameter to TRUE.
- Go back to the table table where you applied the Top N rows.
- Now, we’re going to change the Power Query code. We are going to apply these steps based on the parameter value. So, open the Advanced Editor which you can find in the ribbon.
- Find the line of code which includes the Top N rows. Probably the name of this expression line is “Kept first rows”.
- Now, add an if statement based on the parameter. We can call the parameter by calling the name of this parameter within round brackets.
- As described before, Power Query is an expression-based language. So, each row results in a dataset. In the else part of our if statement, we will refer to the result of the step before we added the Top N rows. So, your line of Power Query code might look something like this:

Now, it is time to try what the results look like. So, change the parameter from true to false and you’ll see that the full dataset will be loaded.
Since you’re still in Power BI desktop, this will be fine. After publishing this to the Power BI service, you want to change the parameter to false to load the full set of data. You can do this by following the steps described in one of my previous blog posts about parameterizing your data source.
Wrapping things up
Applying a Top N rows can be useful in case you want to speed up the loading process of data while you’re developing your solution. It is not only time saving, but also makes it easier to validate if your calculations are correctly since it is easier to check with a smaller dataset.
But, loading a subset of data is only useful when your data source supports query folding. If you’re loading data from a flat file structure or other data source that doesn’t support query folding, the full set of data will be loaded anyway. Still you can apply Top N to make your data validation easier.
Using parameters to decide if the Top N rows will be applied or not, will make it easier to move your solution through the landscape and only load the full set of data in the Power BI service.

Pingback: Don’t let date columns ruin query folding in Power BI – Data – Marc
Pingback: Versioning and CI/CD for Power BI with Azure DevOps – Data – Marc
Pingback: Faster Power BI and Analysis Services Development with Automatic Data Subsets - The Bit Bucket