
Recently, I run into a case where we wanted to combine Direct Query sources with imported data. Well, this functionality is actually called composite models nowadays.
Having that said, let me start with managing some expectations for this post. The title says composite models, but I have to admit, it is not about the to be released composite models feature where you can combine multiple Power BI datasets. Instead of that, it is about combining Direct Query and Import mode in one single dataset.
In this blogpost I will describe more about my use case, why I considered to use some sources on Direct Query, how this combines with Row Level Security and Query Folding.
The case and the question to answer
Recently, I worked on a project with a fairly large dataset, that is processed in Azure by leveraging Azure Synapse. On top of that, we want to build a Power BI report. As we aim for a central solution with many different users across the world, the size of this dataset is also likely to be very huge.
After the data model was built, a nice star schema, vertipaq analyzer* told me that the majority of my model size is in my fact tables (no surprise there) due to a very high cardinality in several columns. I decided to see what composite models can bring to the table here.
As my case involves many different users that are only allowed to see their own data, I also have Row Level Security applied. Reading the Microsoft documentation on Direct Query, it tells me that data will be cached in Power BI upon load. It also says that this does not apply if RLS is configured.
Does this mean that the query will be folded back to the source and the RLS filter will be applied on the source side? I hope so! Let’s see…
* If you are not familiar with vertipaq analyzer and investigating your model size, I recommend you to look a this blogpost that was recently posted by Gilbert Quevauvilliers.
Sample case
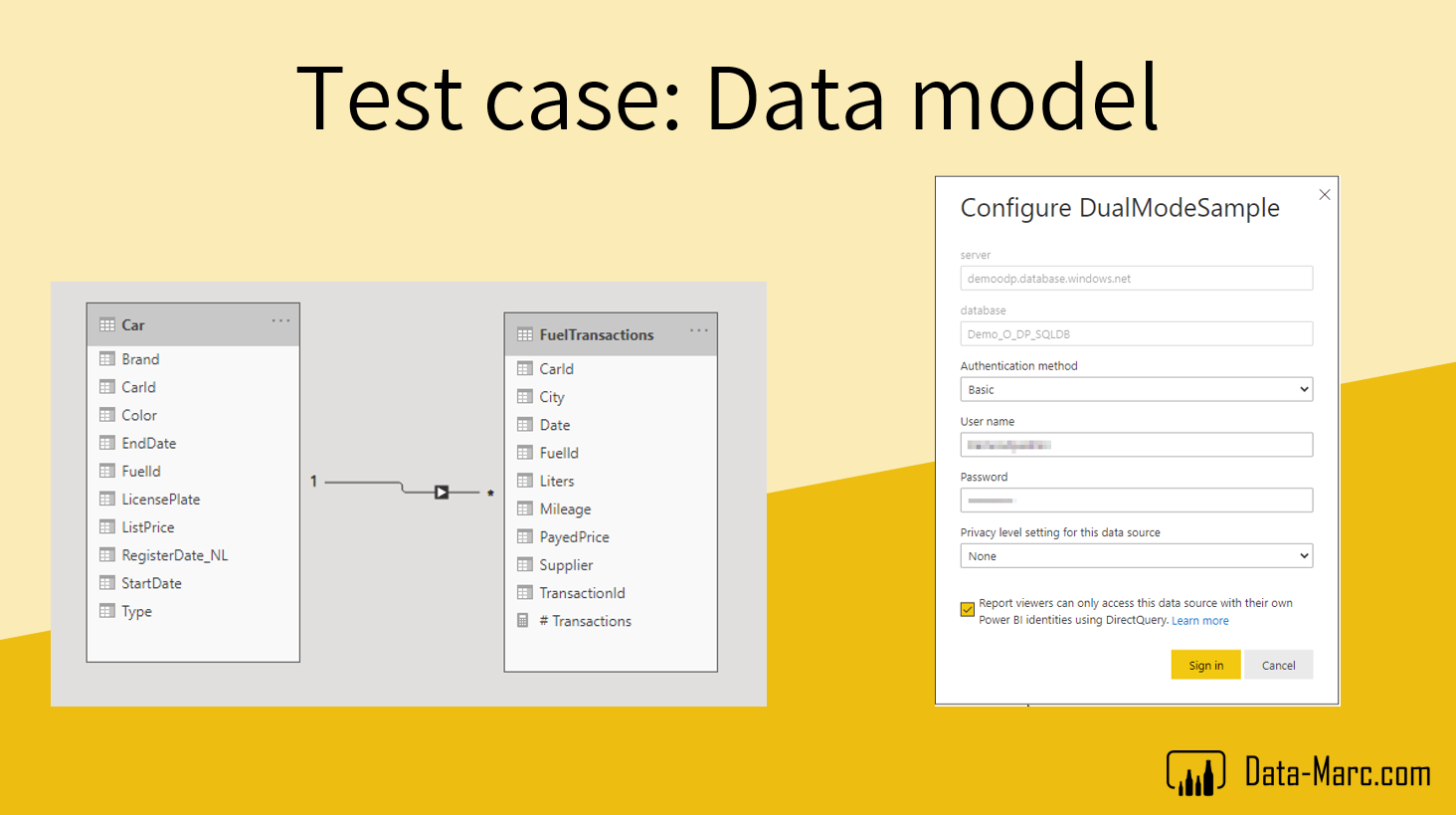
In order to try this, I setup a fairly simple dataset in an Azure SQL Database. This database simply contains some data about fuel transactions that belong to a car. So, one fact table and one dimensional table.
- Fact table, Fuel Transactions, is set to Direct Query
- Dimensional table, Car, is set to import mode.
It shows Dual in the advanced tab in the model view.
Fairly simple row level security is applied to test this scenario. I simply added two roles that filter on the dimensional table based on car brand. So one role for “Kia” and one role for “Peugeot”.
The question we want to answer
As the dimensional table is imported, I would expect the user to always see the data for this table, according to the row level security role assigned. On top of that, I would expect the data from the fact table to be filtered based on the row level security role, where this will be pushed down to the underlying data source.
Besides that, Power BI also offers a way to push down the user authentication to the source, so the security will be handled in the data source instead of Power BI. This only applies to Direct Query and permissions should be granted in the source for every user that will consume the report. For imported tables, other authentication methods can still be used.
So, we want to answer the following questions:
- Will Power BI be able to fold the query coming from row level security and push down to the database?
- What happens with row level security if the dataset configuration forces users to use their own Power BI identity to read from the source?
Tracing Power BI behavior
As I have configured the dataset, row level security and data source credentials as described above, it is time to start testing. I will describe different test cases and the query that is executed on the SQL database.
Test 1: User access report without sufficient privileges in the database
In the first scenario, we granted a user access to the report and added the user to the Row Level Security role for car brand “Peugeot”.
- The user will be able to see the imported data, filtered based on the RLS role assigned.
- The user will not be able to see any of the data coming from the Direct Query tables, as the user does not have sufficient privileges yet in the SQL database. Each visual that uses Direct Query data will show an error.

To fix this, we need to make sure that the user has access to the SQL Database with at least read access. The dataset settings told us that the Power BI identity will be used, which is an Azure Active Directory identity (AAD). So, we need to make sure that the SQL Database is also connected to AAD. The below code snippet helps you to get this sorted.
-- create user reading from active directory
CREATE USER [<email address>]
FROM EXTERNAL PROVIDER
-- grant read access to above created user
ALTER ROLE db_datareader
ADD MEMBER [<email address>]; After applying above steps, the user should have read access to the entire database. There are more efficient and secure ways to do this of course, by only granting read access to tables leveraged in Direct Query mode. You can do this by using something like below snippet.
-- grant read access to a specific table
GRANT SELECT ON <DatabaseName>.<TableName> TO [<email address]Test 2: What query is executed on the SQL when the user opens the report?
As we granted access to the user, the data will be shown in the report according to the row level security applied. That is all working as expected!
Now, we want to know if the RLS filter is also pushed down, using query folding, to the query executed on the SQL database. In my case it is a fairly simple and small dataset, but imagine that we have a trillion row dataset, than it would be sub-optimal if Power BI first caches the data and then applies the RLS filters. But let’s not run into conclusions to soon and have a look on what is actually happening.
There are various ways to monitor the executed queries on a SQL database, for example use SQL profiler or any other tool. I simply went for another approach to monitor the incoming queries by executing the below script using Management Studio.
-- show past 10 executed queries on the database
SELECT TOP(10) creation_time, last_execution_time, [text]
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) AS ST
ORDER BY last_execution_time DESCExecuting above query showed me that Power BI does push down the Row Level Security filter in the WHERE clause of the executed SQL query. Which is a positive outcome of course! Below the query that was actually executed on the SQL database.
SELECT COUNT_BIG(DISTINCT [t1].[TransactionId]) AS [a0]
FROM (
(select [$Table].[TransactionId] as [TransactionId],
[$Table].[CarId] as [CarId],
[$Table].[FuelId] as [FuelId],
[$Table].[PayedPrice] as [PayedPrice],
[$Table].[Liters] as [Liters],
[$Table].[Mileage] as [Mileage],
[$Table].[Date] as [Date],
[$Table].[Supplier] as [Supplier],
[$Table].[City] as [City]
from [dbo].[FuelTransactions] as [$Table]) AS [t1]
LEFT OUTER JOIN (
select
[$Table].[CarId] as [CarId],
[$Table].[Brand] as [Brand],
[$Table].[Type] as [Type],
[$Table].[Color] as [Color],
[$Table].[LicensePlate] as [LicensePlate],
[$Table].[ListPrice] as [ListPrice],
[$Table].[RegisterDate_NL] as [RegisterDate_NL],
[$Table].[StartDate] as [StartDate],
[$Table].[EndDate] as [EndDate],
[$Table].[FuelId] as [FuelId]
from [dbo].[Car] as [$Table]) AS [t0]
on ( [t1].[CarId] = [t0].[CarId] ) )
WHERE ( ([t0].[Brand] IN (N'Peugeot')) ) 
Conclusion
Coming back to the questions I defined in the beginning, we can conclude that Power BI does fold the query from Row Level Security into a native query executed on the source side. So the caching of data is as optimal as possible.
If authentication is handled using the Power BI identity, it is important that the source is connected to the Azure Active Directory. This does not make any difference for the query to fold or not.
Although the documentation already told us that the cache is not shared in this scenario, it is good to know that even row level security filters are pushed down to the source using query folding.
Still, my best practice will remain the same. Always use import mode unless… Simply to have the full flexibility and capability of Power BI and reach the optimal end-user experience.

Pingback: Query Folding in Direct Query Plus Import Scenarios – Curated SQL
Hi Marc, Thanks for the post. I went through the same use case with my client once. One thing to remember when you turn on Single Sign On On direct query, it applies to all reports pointing towards the same sql server. So if you have 5 reports and 4 using service accounts to connect to the server with Oauth and 1 report using connected to the same server and ticked SSO on all 5 reports will be on SSO. I run the rest and I was quite surprised.
LikeLike
Hi,
This sounds a bit weird to me… So if I understand correctly, you had 5 different pbix files, and by changing one to SSO, they all changed? Was it connected to a gateway in your case?
As every dataset has its own settings, I would expect the settings to apply to only one dataset (so 1 pbix). Unless you changed gateway settings that force the SSO to happen in Direct Query mode.
Eager to hear more about your case.
Marc
LikeLike
Thank you for this post.
Despite it is old post but this case is vital in many cases.
Up to my understanding, queries in Direct Query tables of the composite models are all pushed to the data source (i.e. 100% query folding but without WHERE clause). Missing WHERE might trigger another problem which is high overhead on the data source, and eventually bad and slow report.
While for import portion, query folding might happen depending on the transformation type.
In my opinion, we can improve the performance by leverage incremental refresh.
Composite models are good when you have multiple data sources but you can’t merge them into one model due to lack of time or incompatibility issues
Thank you
LikeLike
Hi Ahmed,
Comparing composite models and incremental refesh is not entirely fair in my opinion. Both features serve a different purpose.
Though, it fully depends on your use case if you can exchange the features and will be able to succeed with that.
–Marc
LikeLike
With RLS, when you add additional filters either via slicers or the filter pane, are you seeing those pushed down to the database query as well? I am running into an issue where PowerBI is pushing down the RLS filters but not page filters so am running into 1M record limits.
LikeLike
Usually this comes down to how DAX expressions are built up. Consider trying some simple expressions to check the behavior and folding of those.
–Marc
LikeLike